New LLM Vulnerability Discovered that Exposes Chat Responses
A new attack against LLMs uncovers a vulnerability that potentially allows attackers to intercept AI chat responses.
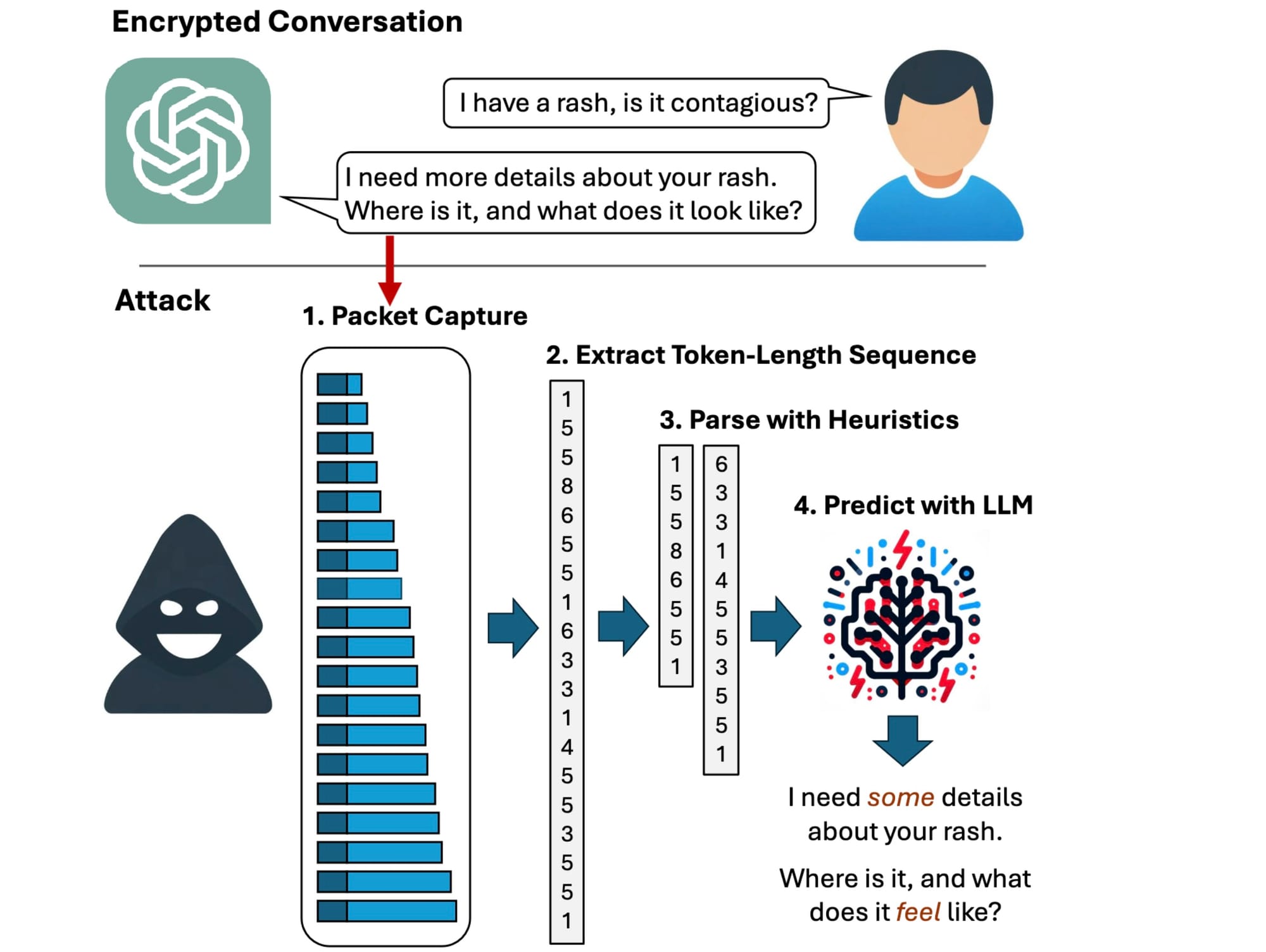
Recently, a group of researchers at Ben Gurion University uncovered a vulnerability in large language model (LLM) based assistants, shedding light on a potential risks users face. In their paper titled “What Was Your Prompt? A Remote Keylogging Attack on AI Assistants,” they detailed a method which allows attackers to intercept and understand a conversation by exploiting weaknesses in the way AI assistants transmit data.
Summary of the Vulnerability
A vulnerability in AI assistants allows attackers to eavesdrop on conversations by intercepting network traffic. By analyzing the length of data packets exchanged between the AI assistant and the user, attackers can decipher encrypted responses, exposing sensitive information. This vulnerability arises due to the predictable way AI assistants transmit data, allowing attackers to infer the content of messages despite encryption. This vulnerability currently affect all widely available chat-based LLMs, with the exception of Google Gemini.
Conditions for Exploitation
- AI Assistant in Streaming Mode: The vulnerability requires the AI assistant to operate in streaming mode, where responses are transmitted token by token in real-time.
- Interception of Network Traffic: Attackers need to intercept network traffic between the AI assistant and the user, which can be achieved through public networks or within an Internet Service Provider (ISP).
The exposure of sensitive information exchanged during these interactions, including personal conversations and business discussions, poses a serious threat to user privacy and confidentiality.
How Threat.Digital Mitigates this Vulnerability
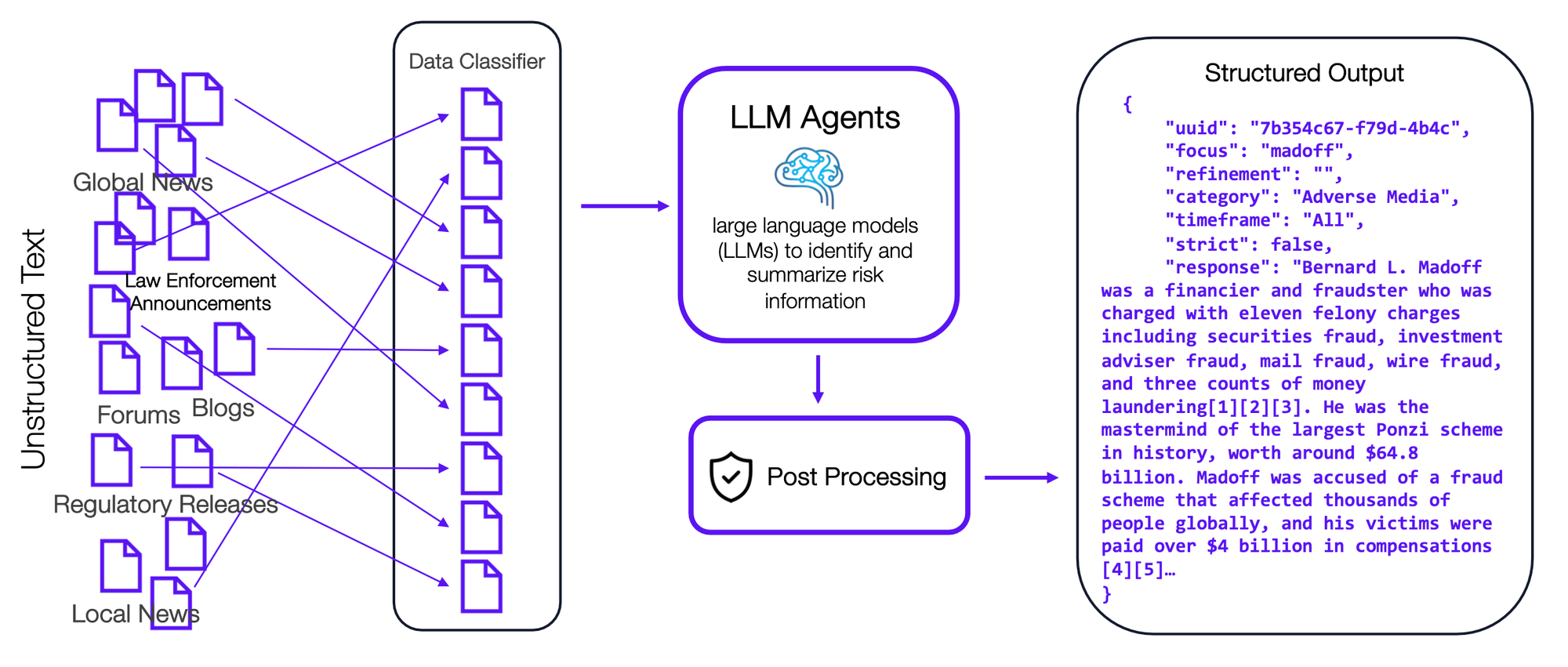
Our flagship service, DiligenAI, leverages LLMs as a core aspect of the offering. That's why we've integrated advanced security measures into the tool. In addition to not streaming responses which already mitigates this attack, here's how DiligenAI addresses these types of vulnerabilities:
- Post-Processing Step: Before returning responses to users, DiligenAI incorporates a post-processing step that adds an extra layer of security. By standardizing and adding guardrail measures to LLM responses, DiligenAI enhances user privacy and ensures that interactions remain secure.
Staying Ahead of Threats
As the AI landscape continues to evolve, so do the threats that organizations and individuals face. At Threat.Digital, we remain committed to staying ahead of these threats and equipping our clients with the tools and knowledge they need to navigate the AI world safely. By continuously monitoring for vulnerabilities and implementing proactive security measures like those found in DiligenAI, we help ensure that users can interact with AI assistants and other digital technologies with confidence.