Mapping Sanction Ownership Networks for the BIS 50% Rule
How we turned our network research system into a structured ownership mapping service for BIS 50% Rule compliance
When we plan our development roadmap, we usually prioritize two things:
- Stuff we think would be cool
- Things clients tell us they actually need
When we're lucky, we get both at the same time.
Starting mid-2025, we began hearing more and more from clients and prospects that they were looking for a way to comply with the upcoming BIS 50% ownership rule.
The challenge for customers is that the data doesn’t exist in one place, and in some cases, it doesn’t really exist at all in a structured form.
Ownership information is spread across jurisdictions, filings, disclosures, media reporting, and other sources. Pulling that together into something usable takes significant effort, and even then coverage is uneven. Structures change, companies reorganize, and new entities appear that may not yet be captured in any dataset.
The compliance challenge for companies
For most organizations, the challenge comes down to two practical options.
The first option is to conduct human-level due diligence on each name. This will produce strong results, but it is time-consuming and expensive. When organizations need to evaluate hundreds of thousands of companies, this approach quickly becomes cost-prohibitive and difficult to maintain over time.
The second option is to purchase related-party or ownership datasets from existing providers. These datasets can be valuable and are often built through detailed research. However, they can also be expensive, and like any dataset, they will not capture every relevant relationship, particularly as ownership structures change or new entities emerge.
Based on the amount of inbound interest we received for solutions, neither of these options were working for a large number of companies. Could there be another option for clients?
The starting point: we already had the underlying research system
The heart of what we do is build automated research systems for due diligence, financial crime, and compliance teams.
Last year, we released our Network Report, which performs on-demand automated relationship research using open-source information and builds networked views of ownership, control, affiliates, executives, and related entities. The original goal of that product was broader: help teams identify hidden risk around a company or person by expanding beyond the immediate subject and recursively researching connected parties.
This is exactly the type of information needed to comply with the BIS 50% Rule. The only difference is that instead of running the research on demand for a single input name, we needed to invert the process.
Rather than starting with one company and expanding outward, we start with a seed list of relevant sanctioned parties and build ownership and relationship networks for each of them. That produces a structured view of entities that may fall within scope, based on ownership and control relationships identified through the same automated research approach.
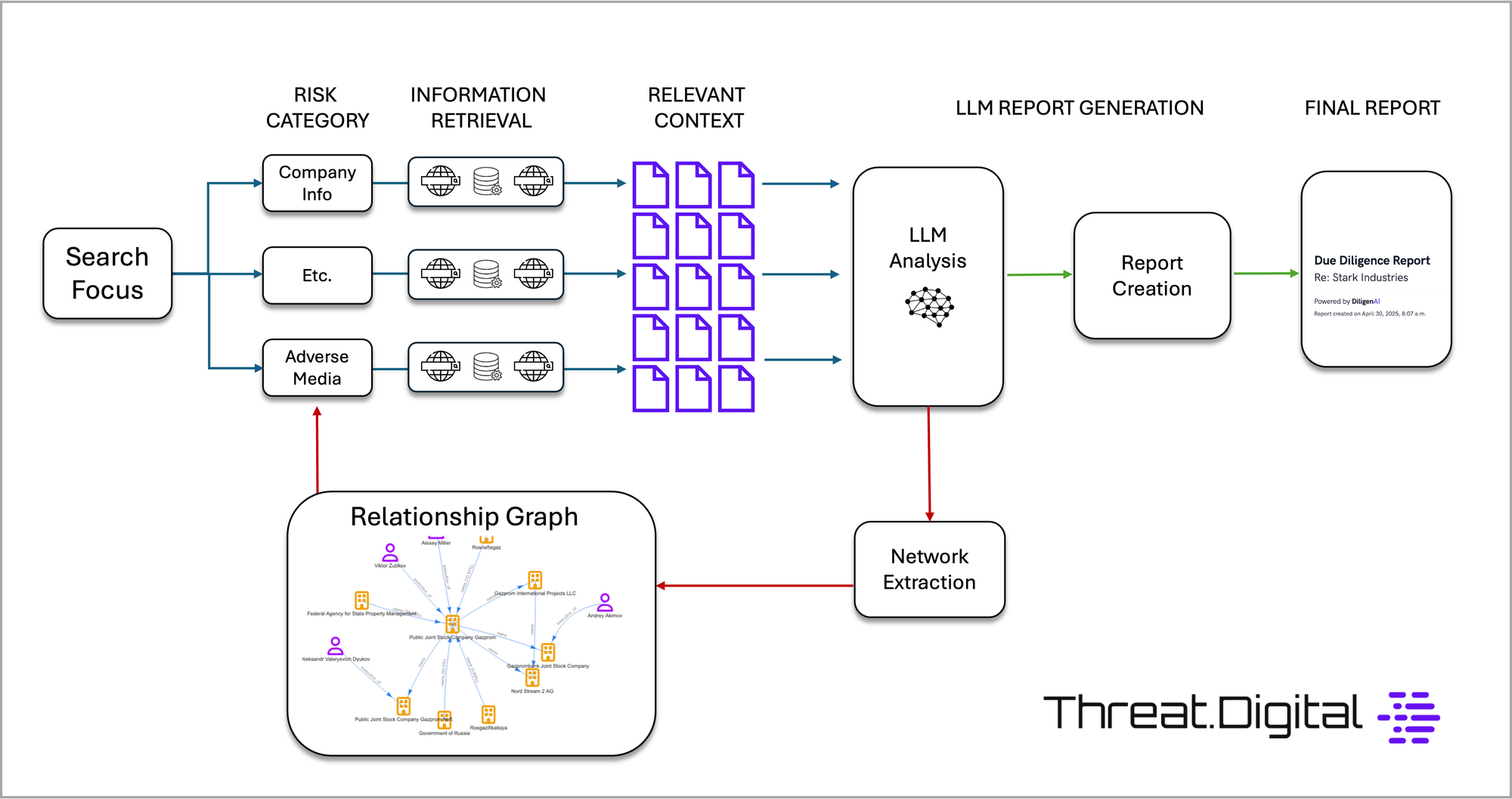
What we built
The workflow was simple. We start with a seed list of listed parties. For each one, the system runs automated research to identify ownership and control relationships, extracts those relationships into a structured graph, and then consolidates the results into exportable data and graph outputs.
The system extracts relationship evidence into a defined ontology, links the results back to source material, and then resolves those extracted nodes into a consolidated network so that the output is usable as data rather than just narrative text.

The result is a service that can take a sanctions seed list and produce:
- identified related parties,
- ownership and control relationships,
- consolidated party and relationship data file exports,
- and graph outputs that can be reviewed visually or consumed downstream.
The output is a structured set of files: one containing the consolidated related parties, and another containing the relationships between those parties. That makes the result usable for higher-volume screening and downstream compliance workflows, not just manual review.

So AI works perfectly all the time?
It does not. Working with complex AI systems is as much art as science, which is one reason it is difficult to turn them into reliable and productized solutions. Luckily, that is exactly what we have been delivering for the past three years.
One of the biggest challenges in this type of research is disambiguation between entities and individuals with the same or similar names, especially with limited source data and at scale.
Take the example below, taken directly from the BIS Entity List:
| Source | Entity List (EL) - Bureau of Industry and Security |
| Start Date | 2023-03-06T00:00:00Z |
| Federal Register Notice | 88 FR 13675 |
| Name | Ministry of Transport and Communications |
| License Requirement | For all items subject to the EAR. (See §§744.11 of the EAR) |
| License Policy | Case-by-case review for telecommunications infrastructure items described in Category 5 Part 1 or Category 5 Part 2 and consumer communications devices identified in § 740.19; Presumption of denial for all other items subject to the EAR |
| Score | 90 |
| Source List URL | https://www.bis.gov/regulations/ear/744#supplement-4-744 |
| Source Information URL | https://www.bis.gov/licensing/guidance-on-end-user-and-end-use-controls-and-us-person-controls |
| Addresses |
|
Due to the commonality of the name, running it through the initial process led to the messy situation below that incorrectly mapped the relationships to the Finnish Ministry of Transport (vs the sanctioned one from Myanmar). That would not work.
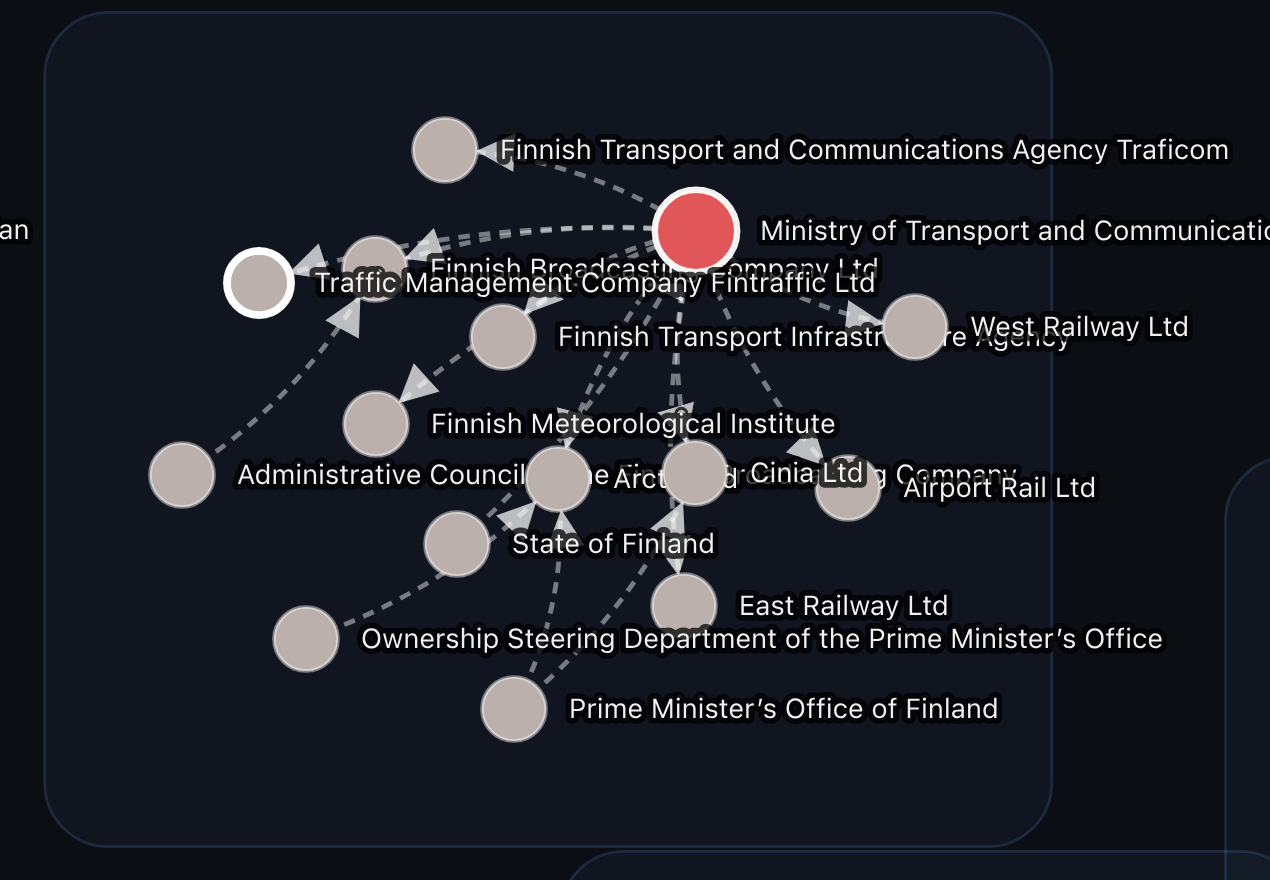
So within the research pipeline, we built a quality control AI agent to review every network.
Its role is closer to quality assurance than research. The research layer identifies candidate entities and relationships. The QC layer reviews whether a merge or linkage is likely valid, flags questionable joins, and helps separate stronger consolidations from weaker ones.

The main value is that it acts as a guardrail, and the information can be integrated back into the research process. It gives us a way to confidently scale the system without letting quality drift as volume increases.
How this compares to existing approaches
There are already vendors and research teams working on ownership datasets for sanctions and export controls. Some rely heavily on human research. Others are built around corporate registry and filing data. Those approaches have real strengths.
Human research can be careful, nuanced, and strong on edge cases. Registry-focused solutions can provide high-confidence structured ownership where the underlying filings are available and current.
Our approach is different. It is built around automated research, structured extraction, and network consolidation. That makes it useful for broader coverage, faster refresh cycles, and cases where relevant information is dispersed across open sources rather than sitting neatly in a corporate record.
That does not make it a replacement for every other method. Open-source relationship discovery is not the same thing as a definitive corporate registry. Some relationships are ambiguous, some ownership percentages are unavailable, and some structures remain opaque. There will be cases where a human researcher or a high-quality registry source has something we do not, and cases where our approach surfaces a connection they miss.
What comes next
Now that we have a base data processing pipeline, the next step is to expand and enrich it across additional structured information sources, including corporate records. The goal is to use the same underlying process to improve coverage, support deeper research recursion, and increase scale.
We also plan to extend the model across additional sanctions seed datasets, including the OFAC SDN list. That is a natural next step, although the OFAC 50% Rule is not identical to the BIS ownership framework and has its own requirements. The advantage of building this as a service on top of our existing network research infrastructure is that we can apply the same core workflow across new datasets and continue improving the network over time.
If you are interested in learning more about this or any other of our solutions, please feel free to send us a note here.